 I participated in an interesting conversation on Function Points and Agile with members of the software development group at a federal agency recently. We, the DCG team, were explaining how we would start the process of measuring how much value they are delivering from software development by measuring how much functionality they are delivering in function points. For an organization with immature metrics and, perhaps, lack of user trust, this starting point takes the question of productivity off of the table to allow us to move on to end user value delivery
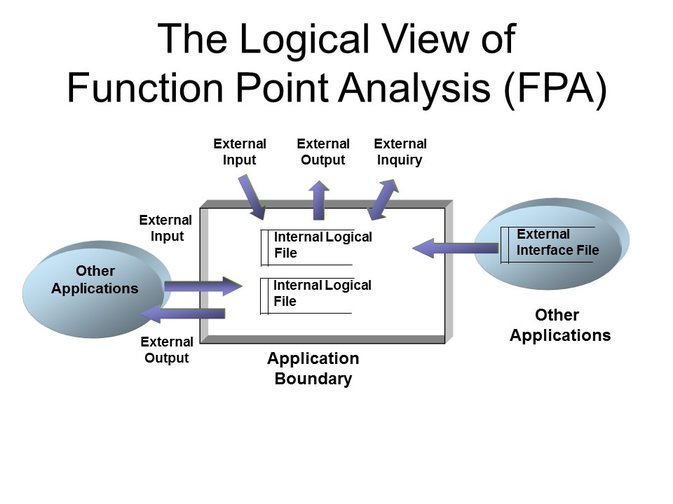
All of the participants in the meeting quickly recognized the value of having a standard metric, function points, to measure the size of the functionality being delivered (and with SNAP – the non-functional size too) but I could see on their faces the sort of trusting disbelief that might be associated with my pulling a rabbit out of my bag. Some of the participants in the meeting were not familiar with function points and asked for a quick, five minute explanation. I get asked this a lot so here it is (before I get inundated with corrections – I know – this is an over-simplification): Imagine a software application and draw an imaginary boundary around it in your mind to include all its functionality but not the functionality of other applications that it communicates with or draws information from. Now consider the diagram below. From a user perspective, looking at the application from outside the application boundary, I can interact with the application in three ways, called transaction functions: external inputs (EIs), external outputs (Eos) and external inquiries (same as input and output but with no change of data or state – EQs). From within the application, I can access data in two places – inside the application boundary or outside the application boundary. My interactions with these files are the two types of data functions: internal logical files (ILFs) where data is stored within the application boundary and external interface files (EIFs) where data is stored outside our application boundary. Most of you will be able to easily imagine that these five types of user interaction with our application can be more or less complex. If I want to produce a function point count, the next step is to consider the first of the transactions that the user wishes to perform on the application (as defined in the requirements, user stories or whatever) and to identify how many of each of the five function types is involved in the transaction and how complex that involvement is (low, average or high). Predetermined rules govern the weights that apply to each function type based on the complexity of the function in this transaction. With all this information gathered, we can calculate the number of function points using the simple table shown below. Function Point Counting Weights Type Low Avg High Total EI __ x 3 +__ x 4 +__ x 6 =___ EO __ x 4 +__ x 5 +__ x 7 =___ EQ __ x 3 +__ x 4 +__ x 6 =___ ILF __ x 7 +__ x10 +__ x15 =___ EIF __ x 5 +__ x 7 +__ x10 =___ Total____ One of the participants offered a very perceptive observation, “Isn’t this a lot of work for every user story in Agile?” It could be. In practice though, by the time a user story is defined and understood, the software problem has been decomposed to the point where identifying the FPA functions and complexities is fairly simple. That said, we don’t recommend this for all agile team members. Story points work fine for most agile teams. Where function points (and SNAP) can and must be used for Agile is where there is a need to aggregate the delivered functionality (and non-functional elements) into higher level metrics for reporting to management. This level of function point analysis is often better done by a separate, central team rather than the agile team members themselves. This post was originally published at https://www.softwarevalue.com/insights/blog/posts/2017/january/function Comments are closed.
|
