 Software brings tremendous value to organizations, but in today’s day and age, it also carries significant risk. Malicious cyberattacks continue to rise at a rapid pace. According to the Identity Theft Resource Center and CyberScout, data breaches increased by 40 percent in 2016 – that’s after a record year in 2015. With the ongoing upsurge in data breaches, software can be seen by many as a potential liability for an organization. We are such a data-driven economy today that criminals have realized that they can cause serious damages to companies, governments and other entities by hacking into their information systems and stealing, corrupting or deleting valuable data. These breaches are extremely costly to organizations – not only financially, but also to their reputations.
Just look at Target. In 2013, hackers stole credit card numbers of 110 million customers costing the retail giant approximately $162 million, in addition to a decrease in sales and a black eye to their reputation (for a short period of time). It’s no wonder that “94 percent of CISOs are concerned about breaches in their publicly facing assets in the next 12 months, particularly within their applications,” according to a January 2017 Bugcrowd study. However, despite these concerns, another survey of over 500 IT decision makers found that 83 percent of the respondents actually release their code before testing it or resolving known weaknesses (Veracode, September 2016). Software is typically at the foundation of all cybersecurity attacks. In fact, the Software Engineering Institute stated that 90 percent of reported security incidents result from exploits against defects in the design or code of software. If a network router is hacked, most likely the hacker went through the router’s software, not hardware. These breaches can pose such a significant threat to an organization’s value that software developers must make application security an integral part of the software development lifecycle. By finding and fixing vulnerabilities early in the software development lifecycle, there is less risk to the business and more potential for increased business value from the software. For example, Adobe Flash player is a product used by many websites to enable interactivity and multimedia. In 2015, it had more than 300 patches (TechBeacon’s Application Security Buyer’s Guide). Developing these patches is a resource drain (both time and money). On balance though the risk Adobe would run by not providing these patches could be significant and negatively impact the Adobe’s value as well as the value of the organizations using its product. So, if an application has, let’s say, 500 known weaknesses, the organization may not have the time or money to fix all of them before an imminent release. They need to collaborate with the business unit and determine which vulnerabilities pose the highest risk to the business (negative business value) and which ones, if remediated, will help to deliver the most value to the business if they are fixed. It is not unusual for developers to fix those vulnerabilities that are easiest to resolve; however, it is critical to take a step back and prioritize identified vulnerabilities based on business value. This post originally appeared at https://www.softwarevalue.com/insights/blog/posts/2017/february/how-does-cybersecurity-drive-the-business-value-of-software/ 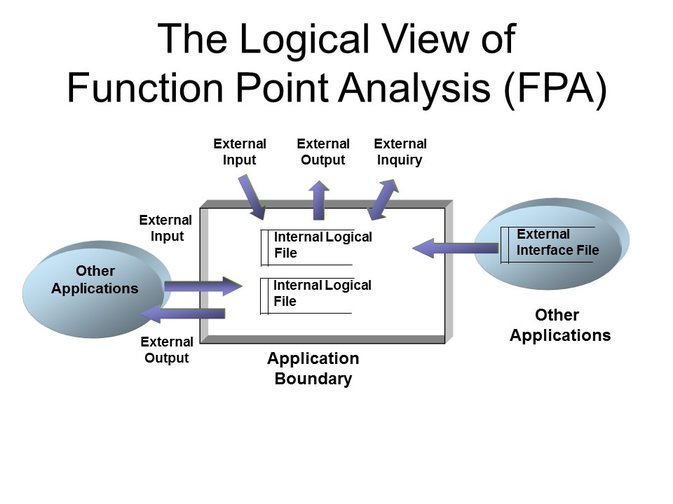 I participated in an interesting conversation on Function Points and Agile with members of the software development group at a federal agency recently. We, the DCG team, were explaining how we would start the process of measuring how much value they are delivering from software development by measuring how much functionality they are delivering in function points. For an organization with immature metrics and, perhaps, lack of user trust, this starting point takes the question of productivity off of the table to allow us to move on to end user value delivery
All of the participants in the meeting quickly recognized the value of having a standard metric, function points, to measure the size of the functionality being delivered (and with SNAP – the non-functional size too) but I could see on their faces the sort of trusting disbelief that might be associated with my pulling a rabbit out of my bag. Some of the participants in the meeting were not familiar with function points and asked for a quick, five minute explanation. I get asked this a lot so here it is (before I get inundated with corrections – I know – this is an over-simplification): Imagine a software application and draw an imaginary boundary around it in your mind to include all its functionality but not the functionality of other applications that it communicates with or draws information from. Now consider the diagram below. From a user perspective, looking at the application from outside the application boundary, I can interact with the application in three ways, called transaction functions: external inputs (EIs), external outputs (Eos) and external inquiries (same as input and output but with no change of data or state – EQs). From within the application, I can access data in two places – inside the application boundary or outside the application boundary. My interactions with these files are the two types of data functions: internal logical files (ILFs) where data is stored within the application boundary and external interface files (EIFs) where data is stored outside our application boundary. Most of you will be able to easily imagine that these five types of user interaction with our application can be more or less complex. If I want to produce a function point count, the next step is to consider the first of the transactions that the user wishes to perform on the application (as defined in the requirements, user stories or whatever) and to identify how many of each of the five function types is involved in the transaction and how complex that involvement is (low, average or high). Predetermined rules govern the weights that apply to each function type based on the complexity of the function in this transaction. With all this information gathered, we can calculate the number of function points using the simple table shown below. Function Point Counting Weights Type Low Avg High Total EI __ x 3 +__ x 4 +__ x 6 =___ EO __ x 4 +__ x 5 +__ x 7 =___ EQ __ x 3 +__ x 4 +__ x 6 =___ ILF __ x 7 +__ x10 +__ x15 =___ EIF __ x 5 +__ x 7 +__ x10 =___ Total____ One of the participants offered a very perceptive observation, “Isn’t this a lot of work for every user story in Agile?” It could be. In practice though, by the time a user story is defined and understood, the software problem has been decomposed to the point where identifying the FPA functions and complexities is fairly simple. That said, we don’t recommend this for all agile team members. Story points work fine for most agile teams. Where function points (and SNAP) can and must be used for Agile is where there is a need to aggregate the delivered functionality (and non-functional elements) into higher level metrics for reporting to management. This level of function point analysis is often better done by a separate, central team rather than the agile team members themselves. This post was originally published at https://www.softwarevalue.com/insights/blog/posts/2017/january/function  Outsourcing software development projects requires vigilance in order to realize the anticipated gains. The hard-fought negotiations to ensure a little bit less cost for the client with a worthwhile profit for the vendor are over for another year or two and the actual work can (re)commence.
What impact will the new software development outsourcing contract have on the behavior of the vendor? Probably the vendor will be looking to save costs to regain lost margin. With the best intentions in the world, this probably means quality is at risk, even if only in the short term. Why? Because the vendor will probably choose to do one, or all, of the following: Push more work through the same team: introduce new, cheaper resources to the team; cut back on testing. How can a client monitor for these software vendor management changes? First and foremost, you need good data. It is not helpful to start to gather data after you think you might have detected a problem with delivered code. The only data that will be useful in a discussion about diminishing quality from development outsourcing is trend data (I will return to this point at the end). That means that the client must be capturing and analyzing data continuously – even in the good times. It you tell me that the quality of my code has dropped off recently, I will not believe you unless you can show me concrete data showing me when and how it was better before. What sort of data? The level of defects found by severity in any acceptance testing should be included. However, with many clients these days having only limited software development capabilities themselves, I would also recommend that all delivered code should be passed through a reputable static code analysis such as CAST, SonarQube or Klocwork. These tools provide a deeper analysis of the quality of the code, new metrics and, by comparison with previous runs on previous code deliveries, the impact of the current code delivery – did it improve or diminish the overall quality of the application being worked on. Clearly, the former is desirable and the latter is a cause for discussion. Some care needs to be taken before diving headlong into an untried static code analyzer. Poor examples of the breed tend to generate many false positives –sometimes so many false positives that the credibility and value of the tool is lost. From personal experience, I also like to see the results of formal code reviews carried out on the code by the developer and one of his colleagues. To quote a RogueWave white paper, “The value of code review is unarguable, which explains why they’re mandated by 53% of today’s software development teams.” Many years ago, during my time managing a large software development group at Sanchez Computer Associates (now part of FIS), we faced the challenge of maintaining and improving code quality on our complex core product while increasing the number of developers to meet demand. Code reviews seemed to be a good answer because we had a group of very experienced developers who could teach and mentor the newcomers. The problem was that the old hands were just as much in demand to get code out of the door so didn’t have the time to review all the code being produced by everyone else. They, not I, came up with a good compromise. They devised a set of programming standards in the form of a checklist that every programmer, including the most experienced developers would apply to their code before unit test. This caught a lot of minor problems through the simple repetitive reminder exercise. Next, the programmer would do a quick review of their checklist and code with a colleague who could do quick “spot checks.” Finally, if any coding defects were discovered in subsequent test or use, the lessons from these were captured in an updated checklist. From a software vendor management perspective, I see the collection and review of these checklists as being a form of commitment from individual team members that their code is “done.” Returning to my point about trend data, being the only currency for a software vendor management discussion, in my experience these discussions proceed very differently if the data collected before the contract (re)negotiation are used to set some expectations in the contract. Not necessarily service level agreements (SLAs), because these may be reserved for more important issues such as cost, productivity or customer satisfaction, but certainly the recording of an expectation that quality metrics will meet or exceed some average expectations based on prior performance from this software vendor (or the one they are replacing). This post was originally published at https://www.softwarevalue.com/insights/blog/posts/2017/january/software-vendor-management-and-code-quality/ Photo By Markus Spiske (https://unsplash.com/photos/xekxE_VR0Ec) [CC0], via Wikimedia Commons  Software value can take many forms but the ability to respond quickly and flexibly to new business challenges separates “just so” software architecture from high-value software architecture. To this end, over the past 20 years, we have seen many steps down the path from monolithic applications to client-server to service-oriented architectures (SOA). Now, organizations seeking to maximize the business value of their software architectures are adopting microservices architectures.
Microservices, as the name suggests, should represent the smallest unit of functionality that aligns to a core business capability.That’s not to say that each business process or transaction is a single microservice but rather that business processes and transactions are “composed” using microservices. Sounds like SOA? Well, yes, it did to me too, at first. The major difference, I think, is that this time the industry has got out ahead of the curve, learned from the challenges that we all had/have with SOA and built the necessary infrastructure to standardize and support the microservices from the beginning. For example:
This last bullet hints at some of the challenges of a microservice architecture. Development needs to be highly automated with automated deployment to keep track of all the microservices that need to be composed into a particular application and continuous integration. However, the adoption of a microservices approach also requires strong discipline from developers and the devops team. Fortunately, the “small is beautiful” nature of most microservices means that the development teams can (and should) be small so team discipline and communication can be maximized. Implementating a microservices architecture is not something to try on your own for the first time. There a number of companies that have already developed strong experience in architecting and development microservices including our own Spitfire Group who have done a number of implementations including a back-office upgrade for a Real Estate firm. I believe that organizations should seriously consider enhancing the business value of their software by implementing microservices architecture for their “leading edge” products or services. By “Leading edge,” I mean those software-based products or services that are most subject to change as the business environment changes. They are probably customer-facing applications which have to respond to competitive changes in weeks not months. They are probably going to be applications whose software value rests on they’re being fit for purpose all the time. This post was originally published at https://www.softwarevalue.com/insights/blog/posts/2017/january/microservices-in-software-architecture/ |
