 Software estimation in simple terms is the prediction of the cost, effort and/or duration of a software development project based on some foundation of knowledge. Once an estimate is created, a budget is generated from the estimate and the flow of activity (the planning process) runs from the budget.
Software estimation can significantly impact business value because it impacts business planning and budgeting. One challenge is that most organizations have a portfolio of software development work that is larger than they can accomplish and need a mechanism to prioritize the projects based on the value they deliver to the business. This is where estimation can help – they predict the future value of the project to the business and estimate the cost of the project in resources and time. Unfortunately, the estimates are often created by the people that are performing the actual day-to-day work not estimation experts. Worse, new estimates from the people doing the work are typically based on their recall of previous estimates, not on previous project actuals – very few organizations take the time to report the actuals after a project is completed. To most accurately estimate a software development project’s future business value, it is best to generate the estimate based on the actuals from similar past projects and statistical modelling of the parameter that are different for the next project. Of course, an estimate is only an estimate no matter who develops it. You can’t predict all the factors that may require modifications to the plan. This is where the estimation cone of uncertainty comes in. The cone starts wide because there is quite a bit of uncertainty at the beginning around the requirements of a project. As decisions are made and the team discovers some of the unknown challenges that a project presents, then the cone of uncertainty starts to get smaller towards the final estimate. In regards to business value, the cone of uncertainty is significant because of the impact that the rigid adoption of early estimates can have on the budgeting and planning processes, especially if the software development effort is outsourced.I see software estimation as both a form of planning and input to the business planning process. However, there is a a significant cross-section of the development community that believes #NoEstimates is the wave of the future. This is a movement within the Agile community based on the premise that software development is a learning process that will always involve discovery and be influenced by rapid external change. They believe that this dynamic environment of ongoing changes makes detailed, up-front plans a waste of time as software estimates can never be accurate. Using #NoEstimates techniques requires breaking down stories into manageable, predictable chunks so that teams can predictably deliver value. The ability to predictably deliver value provides organizations with the tool to forecast the delivery. In my view, the #NoEstimates philosophy really isn’t not estimating – it is just estimating differently. Whether you use classic estimation methodologies that leverage plans and performance to the plans to generate feedback and guidance, or follow the #NoEstimates mindset that uses both functional software and throughput measures as feedback and guidance – the goal is usually the same. They are both a form of planning and input to the business planning processes that are aimed at driving the business value of each software development initiative. This post originally appeared at https://www.softwarevalue.com/insights/blog/posts/2017/january/how-software-estimation-impacts-business-value/ Scope of Report This month’s report will focus on how to improve estimation practices by incorporating the Software Non- functional Assessment Process (SNAP) developed by the International Function Point User’s Group (IFPUG) into the estimation process. Software Estimation The Issue Software development estimation is not an easy or straightforward activity. Software development is not like making widgets where every deliverable is the same and every time the process is executed it is the same. Software development varies from project to project in requirements definition and what needs to be delivered. In addition, projects can also vary in what processes and methodologies are used as well as the technology itself. Given these variations it can be difficult to come up with a standard, efficient, and accurate way of estimating all software projects. The Partial Solution Software estimation approaches have improved but these have not been widely adopted. Many organizations still rely on a bottom-up approach. For many years, development organizations have used a bottom-up approach to estimation based on expert knowledge. This technique involves looking at all of the tasks that need to be developed and using Subject Mater Experts (SMEs) to determine how much time will be required for each activity. Often organizations ask for input separately, but often a Delphi method is used. The Delphi method was developed in the 1950’s by the Rand Corporation. Per Rand “The Delphi method solicits the opinions of experts through a series of carefully designed questionnaires interspersed with information and feedback in order to establish a convergence of opinion”. As the group converges the theory is that the estimate range will get smaller and become more accurate. This technique, and similarly Agile planning poker, is still utilized, but often is just relying on expert opinion and not data. As software estimation became more critical other techniques began to emerge. In addition to the bottom-up method, organizations began to utilize a top-down approach. This approach involved identifying the total costs and dividing it by the number of various activities that needed to be completed. Initially this approach also was based more on opinion than fact. In both of the above cases the estimates were based on tasks and costs rather than on the deliverable. Most industries quantify what needs to be built/created and then based on historical data determine how long it will take to reproduce. For example, it took one day to build a desk yesterday so the estimate for building the same desk today will also be one day. The software industry needed a way to quantify deliverables in a consistent manner across different types of projects that could be used along with historical data to obtain more accurate estimates. The invention of Function Points (FPs) made this possible. Per the International Function Point User Group (IFPUG), FPs are defined as a unit of measure that quantifies the functional work product of software development. It is expressed in terms of functionality seen by the user and is measured independently of technology. That means that FPs can be used to quantify software deliverables independently of the tools, methods, and personnel used on the project. It provides for a consistent measure allowing data to be collected, analyzed, and used for estimating future projects. With FPs available the top-down methodologies were improved. This technique involves quantifying the FPs for the intended project and then looking at historical data for projects of similar size to identify the average productivity rate (FP/Hour) and determine the estimate for the new project. However, as mentioned above, not every software development project is the same, so additional information is required to determine the most accurate estimate. Although FPs provide an important missing piece of data to assist in estimation, they do not magically make estimation simple. In addition to FP size, the type of project (Enhancement or New Development) and the technology (Web, Client Server, etc.) have a strong influence on the productivity. It is important to segment historical productivity data by FP size, type, and technology to ensure that the correct comparisons are being made. In addition to the deliverable itself, the methodology (waterfall, agile), the experience of personnel, the tools used, and the organizational environment can all influence the effort estimate. Most estimation tools have developed a series of questions surrounding these ‘soft’ attributes that raise or lower the estimate based on the answers. For example, if highly productive tools and reuse are available then the productivity rate should be higher than average and thus require less effort. However, if the staff are new to the tools, then the full benefit may not be realized. Most estimation tools adjust for these variances and are intrinsic to the organizations’ historical data. At this point we have accounted for the functional deliverables and the tools, methods, and personnel involved. So what else is needed? The Rest of the Story Although FPs are a good measure of the functionality that is added, changed, or removed in a software development or enhancement project, there is often project work separate from the FP measurement functionality that cannot be counted under the IFPUG rules. These are typically items that are defined as Non-Functional requirements. As stated in the IFPUG SNAP Assessment Practices Manual (APM), ISO/IEC 24765, Systems and Software Engineering Vocabulary defines non-functional requirements as “a software requirement that describes not what the software will do but how the software will do it. Examples include software performance requirements, software external interface requirements, software design constraints, and software quality constraints. Non-functional requirements are sometimes difficult to test, so they are usually evaluated subjectively.” IFPUG saw an opportunity to fill this estimation gap and developed the Software Non-Functional Assessment Practice (SNAP) as a method to quantify non-functional requirements. SNAP History IFPUG began the SNAP project in 2008 by initially developing an overall framework for measuring non- functional requirements. Beginning in 2009 a team began to define rules for counting SNAP and in 2011 published the first release of the APM. Various organizations beta tested the methodology and provided data and feedback to the IFPUG team to begin statistical analysis. The current version of APM is APM 2.3 and includes definitions, rules, and examples. As with the initial development of FPs, as more SNAP data is provided adjustments will need to be made to the rules to improve accuracy and consistency. SNAP Methodology The SNAP methodology is a standalone process; however, rather than re-invent the wheel, the IFPUG team utilized common definitions and terminology from the IFPUG FP Counting Practices Manual within the SNAP process. This also allows for an easier understanding of SNAP for those that are already familiar with FPs. The SNAP framework is comprised of non-functional categories that are divided into sub-categories and evaluated using specific criteria. Although SNAP is a standalone process it can be used in conjunction with FPs to enhance a software project estimate. The following are the SNAP categories and subcategories assessed: 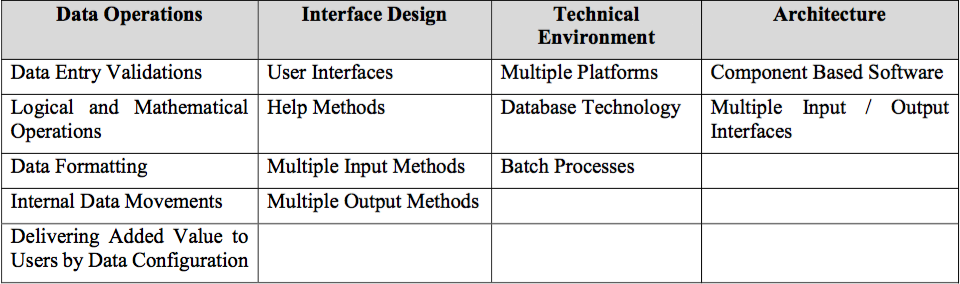 Each sub-category has its’ own definition and assessment calculation. That means that each subcategory should be assessed independently of the others to determine the SNAP points for that subcategory. After all relevant subcategories have been assessed the SNAP points are added together to obtain the total SNAP points for the project. Keep in mind that a non-functional requirement may be implemented using one or more subcategories and a subcategory can be used for many types of non-functional requirements. So the first step in the process is to examine the non-functional requirements and determine which categories/subcategories apply. Then only those categories/subcategories are assessed for the project. With different assessment criteria for each subcategory it is impossible to review them all in this report; however, the following is an example of how to assess subcategory 3.3 Batch Processes: Definition: Batch jobs that are not considered as functional requirements (they do not qualify as transactional functions) can be considered in SNAP. This subcategory allows for the sizing of batch processes which are triggered within the boundary of the application, not resulting in any data crossing the boundary. Snap Counting Unit (SCU): User identified batch job Complexity Parameters: 1. The number of Data Elements (DETs) processed by the job 2. The number of Logical Files (FTRs) referenced or updated by the job SNAP Points calculation:  Result: Scheduling batch job uses 2 FTRs so High complexity. 10*25 DETs= 250 SP >/p> Each non-functional requirement is assessed in this manner for the applicable subcategories and the SP results are added together for the total project SNAP points. SNAP and Estimation Once the SNAP points have been determined they are ready to be used in the software project estimation model. SNAP is used in the historical top-down method of estimating, similar to FPs. The estimator should look at the total SNAP points for the project and look at historical organization data if available, or industry data for projects with similar SNAP points to determine the average productivity rate for non-functional requirements (SNAP/Hours). Once the SNAP/Hour rate is selected the estimate can calculate effort by taking the SNAP points divided by the SNAP/Hour productivity rate. It is important to note that this figure is just the effort for developing/implementing the non-functional requirements. The estimator will still need to develop an effort estimate for the functional requirements. This can be done by taking the FPs divided by the selected FP/Hour productivity rate. Once these two figures are calculated they can be added together to have the total effort estimate for the project. Estimate example:  Note that the SNAP points and the FPs are not added together, just the effort hours. SNAP and FP are two separate metrics and should never be added together. It is also important to make sure that the same functionality is not counted multiple times between SNAP and FPs as that would be ‘double counting’. So, for example, if multiple input/output methods are counted in FPs they should not be counted in SNAP.
This initial estimate is a good place to start; however, it is also good to understand the details behind the SNAP points and FPs to determine if the productivity rate should be adjusted. For instance, with FPs, an enhancement project that is mostly adding functionality would be more productive than a project that is mostly changing existing functionality. Similarly, with SNAP, different categories/subcategories may achieve higher or lower productivity rates. For example, a non-functional requirement for adding Multiple Input Methods would probably be more productive than non-functional requirements related to Data Entry Validations. These are the types of analyses that an organization should conduct with their historical data so that it can be used in future project estimations. FPs have been around for over 30 years so there has been plenty of time for data collection and analysis by organizations and consultants to develop industry trends; but it had to start somewhere. SNAP is a relatively new methodology and therefore has limited industry data that can be used by organizations. As more companies implement SNAP more data will become available to the industry to develop trends. However, that doesn’t mean that an organization needs to wait for industry data. An individual company can start implementing SNAP today and collecting their own historical data, conducting their own analyses, and improving their estimates. Organizational historical data is typically more useful for estimating projects anyway. Conclusion: An estimate is only as good as the information and data available at the time of the estimate. Given this, it is always recommended to use multiple estimation methods (e.g. bottom-up, top-down, Delphi, Historical/Industry data based) to find a consensus for a reasonable estimate. Having historical and/or industry data to base an estimate upon is a huge advantage as opposed to ‘guessing’ what a result may be. Both FP/Hour and SNAP/Hour productivity rates can be used in this fashion to enhance the estimation process. Although the estimation process still isn’t automatic and requires some analysis, having data is always better than not having data. Also, being able to document an estimate with supporting data is always useful when managing projects throughout the life cycle and assessing results after implementation. Sources:
This blog was originally posted at https://www.softwarevalue.com/insights/blog/posts/2016/october/how-can-i-use-snap-to-improve-my-estimation-practices/. #Trusted Advisor, #SNAP, #Software Estimation  I was recently involved in a consulting engagement where Agile methodologies were being implemented with User Stories as the documentation standard. The organization had used function points (FPs) for years on their waterfall projects and were wondering if they could use them for their Agile methodology – and if User Stories would be a good input into the FP counting process. The answer I provided was a resounding “YES.” Having User Stories is actually a huge advantage to counting FPs, especially early in the lifecycle, because User Stories are typically focused on the user perspective, just like FPs.
The only difficulty in using FPs in Agile methodologies is determining what to count and when to count. As with any metric, this always goes back to the purpose. For example, if you want to know the size of the final delivered product, then you count the FPs at the end of the project. If you want to estimate effort for a Sprint or Program Increment (PI), then you need to count at the beginning of the Sprint or PI. The key is defining the purpose early in order to have access to what you need at the time of data collection. When actually counting FPs from User Stories, there are a few tips that help with the process. Depending on the level of the User Stories, more questions or assumptions may be needed to get to an accurate FP count. There are also key words used in User Stories that may help identify FP components (e.g. Maintain, Report, Enter, Select). Often User Stories equate to transactional functions in FPs, so it is important for the FP analyst to identify data functions as they go along. More tips and advice, including real-life examples, will be provided in my upcoming webinar, “Counting Function Points from User Stories,” taking place on Wednesday September 28, 2016 at 12:00 pm EST. Please register here. If you have any questions before the webinar, just leave a comment and I’ll be sure to address them during the presentation. Lori Limbacher Estimation Specialist; Certified Function Point Specialist (CFPS) This blog was originally posted at https://www.softwarevalue.com/insights/blog/posts/2016/september/how-to-count-function-points-from-user-stories/. |
